Go 语言中关于 Unicode、Rune、UTF-8 和 string 的一个问题
Dave Cheney 昨天在推上发了一个 Go 的小测试,问题如下:
#golang pop quiz, what does this program print?
package main import ( "fmt" ) func main() { s := string([]rune{0xf8}) fmt.Println(len(s)) }
答案分布情况如下:
- 0 7.8%
- 1 51.6%
- 2 29%
- 4 11.7%
正确答案应该是2,看来只有不超过 1/3 的人回答正确了。
下面简析一下这个本身很简单的问题,若有错误恳请指正。要详述 Unicode 和 UTF-8 等需要大量的篇幅,本文只是简述。
Unicode
首先值得一提的是 Unicode。Unicode 俗称万国码、统一码等。
Unicode 是一种字符集。 即字符的集合。
它存在的目的是尽最大努力给世界上任何国家、任何文明的文字(或符号、字符)一个编号(一个数字),这个编号被称作码点(Codepoint)。
但是这个编号并不是这个符号在内存中的直接存储方式。
字符是如何在计算机中存储的,决定于采用的编码方式。
UTF-8
UTF-8 就是一种编码方式。
所谓编码方式,就是指:如何将一个 Unicode 字符对应的码点保存在(编码到)内存中。
UTF-8 的长度与 Unicode 的对应关系(来自维基百科):
| Number of bytes | Bits for code point | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0xxxxxxx | |||
| 2 | 11 | U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| 3 | 16 | U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 4 | 21 | U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Rune
Go 语言中用 Rune 这个类型来表示一个字符的码点。
它其实是 int32 的别名而已。也就是说它最大 4 个字节。
string
Go 语言中的 string 保存的是 byte 流。 但并不一定是有效的 UTF-8 字符串。
但是,将 []rune 转换成 string 的时候,语言本身却能保证得到的 string 是有效的 UTF-8 字符串。不正确的字符会被替换成 \xFFFD。(参考:https://golang.org/ref/spec#Conversions_to_and_from_a_string_type)
题目中的 0xF8 如何表示成
0xF8 是一个码点。
从前面的表中可以看出 0xF8 在范围 U+0080 到 U+07FF 之间。所以需要用两个字节来保存。
0xF8 的二进制为 1111 1000。补零对齐:000 1111 1000。将它们保存成 UTF-8 得到:110000011 10111000。
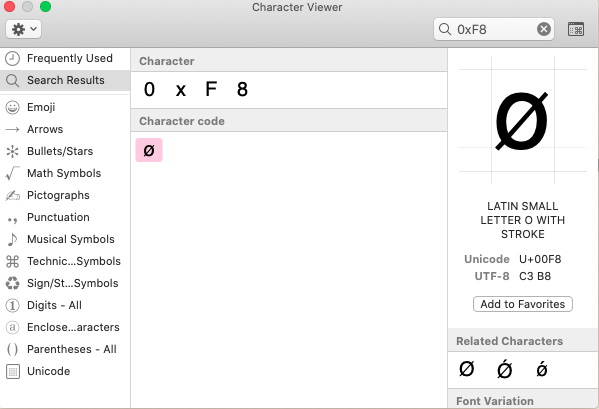
所以:码点 0xF8 保存成 UTF-8 的最终结果为:0xC3 0xB8。
以下是 macOS 的字符查看器的显示结果,可以在右边看到看到确实是这样: